AI for IT Operations
Modern cloud applications typically follow a network topology which consists of multiple interconnected services with complex dependencies. The problem of localizing the root cause of failure during a throttle incident is challenging: a fault in a service will be propagated to all its parent services. Therefore, when an outlier is detected at the organization level, multiple metrics could be detected as abnormal at the same time, and it is difficult to find the culprit.
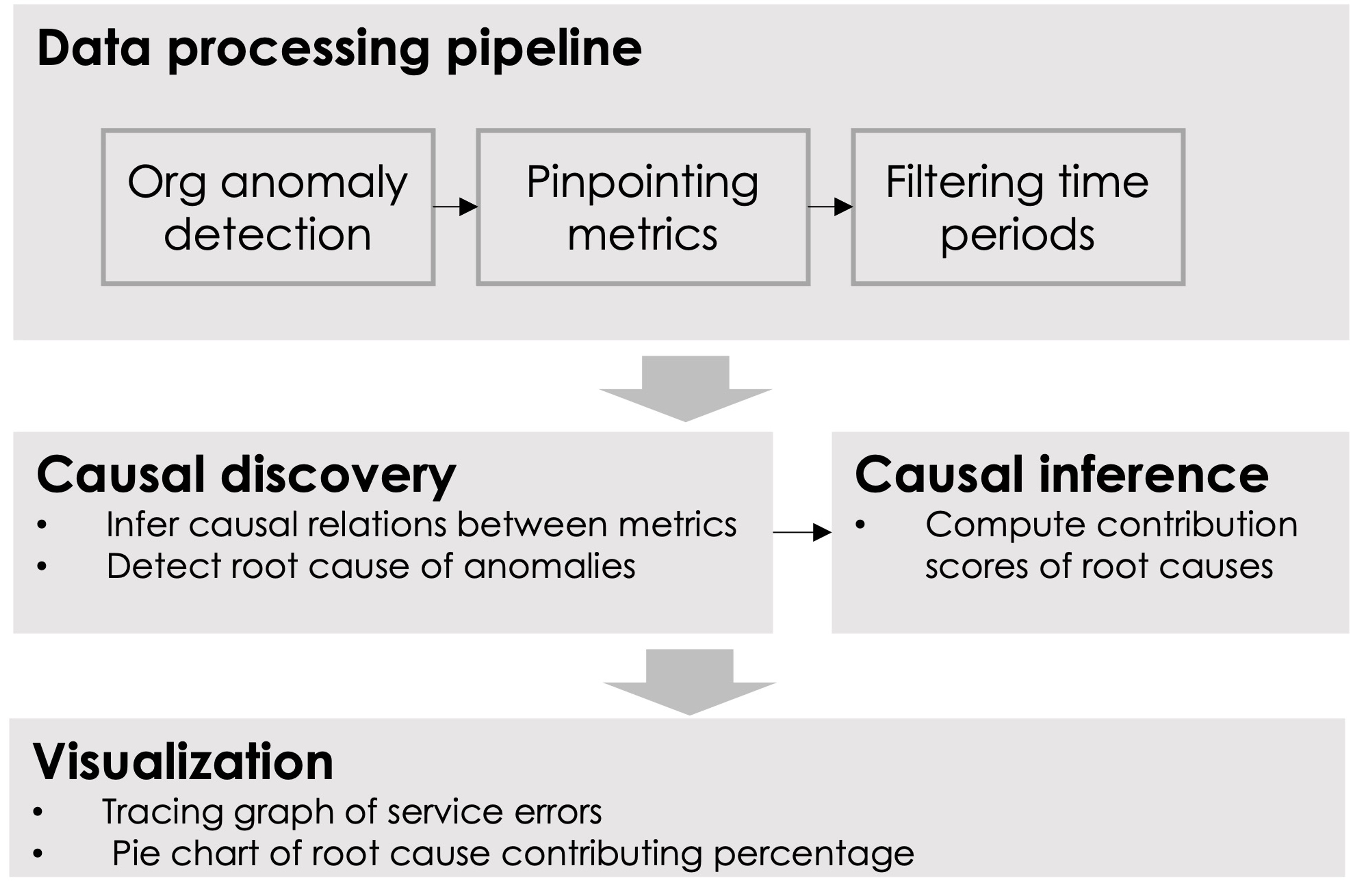
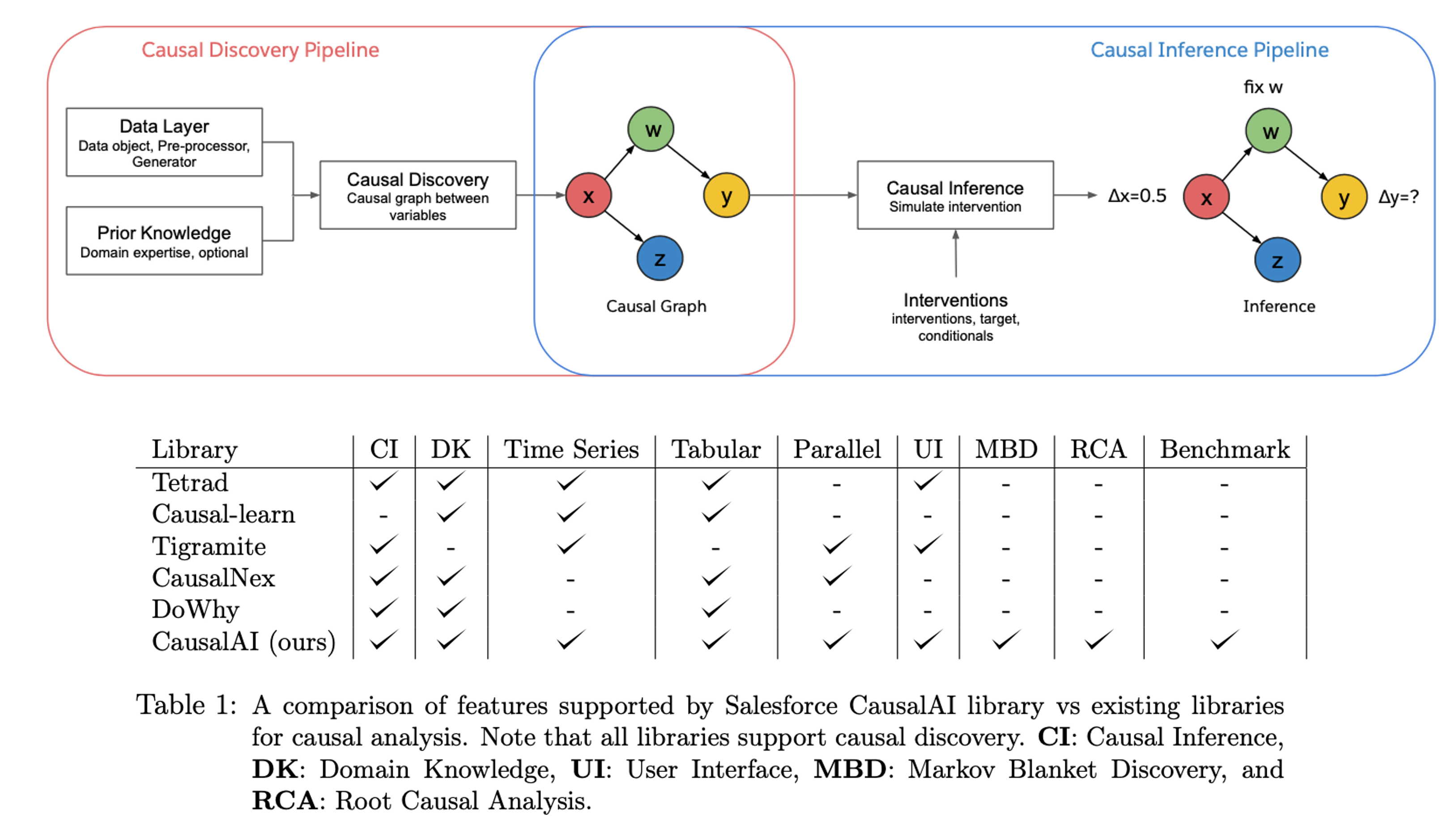
The Contributing Factor Analysis approach solves the challenge by incorporating causal discovery (CD) and causal inference (CI) into analysis, which treats the failure as an intervention on the root cause nodes of the causal graph or Baysian network. The algorithm recognizes a minimal set of intervention targets in the graph, such that the data during normal periods can be converted into the data during incident periods, by propagating the intervention through the discovered causal graph.
We consider the metrics (e.g., dbCPUtime) of each logRecordType or URI pattern as random variables in the graph. We use time-series causal discovery algorithms to: Detect a minimal set of nodes in the graph, whose trend or values are significantly changed before and after the anomaly is fired, as the root causes of the org anomaly; Quantify the contribution of each root cause by calculating how much the trends or values need to be changed, so that the normal data can be converted into data in incident periods.
Solution
We developed a scalable and efficient causal discovery framework, which is able to handle the large-scale graph and time-series data. The key idea is to decompose the causal attribution problem into a set of smaller subproblems, which can be solved in parallel. We also develop a novel optimization algorithm to further improve the efficiency. Check out our library for more details.