PRAct: Optimizing Principled Reasoning and Acting of LLM Agent
















Abstract
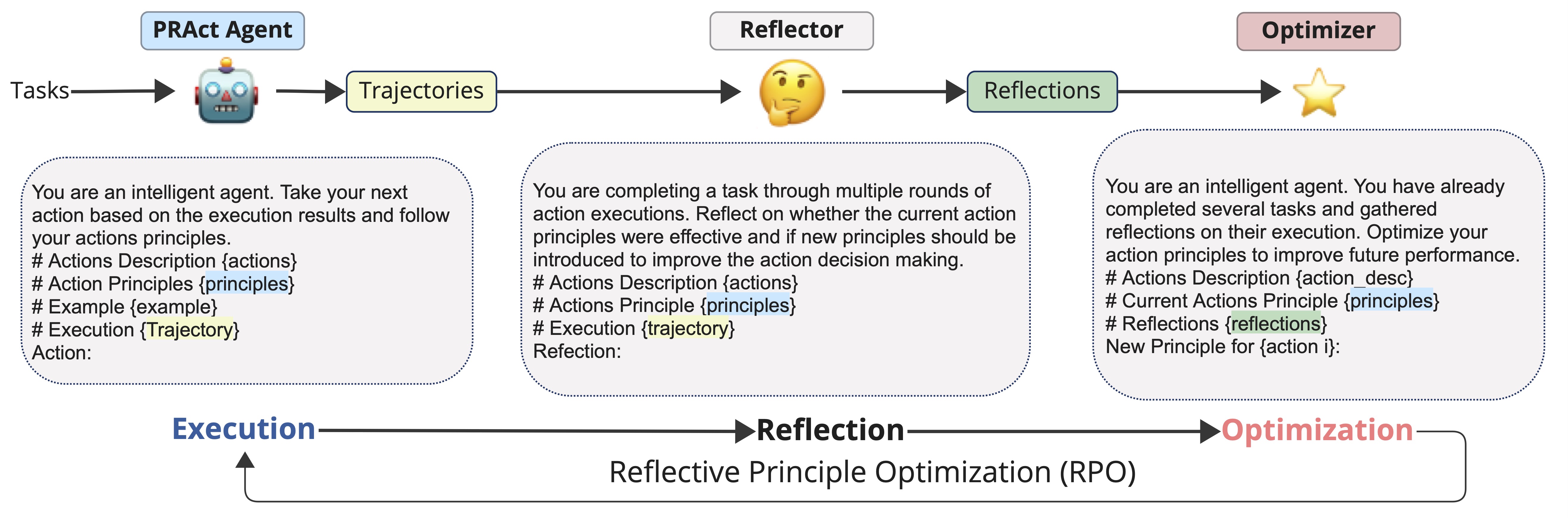
We introduce the Principled Reasoning and Acting (PRAct) framework, a novel method for learning and enforcing action principles from trajectory data. Central to our approach is the use of text gradients from a reflection and optimization engine to derive these action principles. To adapt action principles to specific task requirements, we propose a new optimization framework, Reflective Principle Optimization (RPO). After execution, RPO employs a reflector to critique current action principles and an optimizer to update them accordingly. We investigate the RPO framework under two scenarios: Reward-RPO, which uses environmental rewards for reflection, and Self-RPO, which conducts self-reflection without external rewards. Additionally, we developed two RPO methods, RPO-Traj and RPO-Batch, to adapt to different settings. Experimental results across four environments demonstrate that the PRAct agent, leveraging the RPO framework, can effectively learn and apply action principles to enhance performance.
Framework
BibTeX
@inproceedings{
anonymous2024pract,
title={{PRACT}: Optimizing Principled Reasoning and Acting of {LLM} Agent},
author={Anonymous},
booktitle={The SIGNLL Conference on Computational Natural Language Learning - ARR submissions},
year={2024},
url={https://openreview.net/forum?id=6p8FmlX4F5}
}